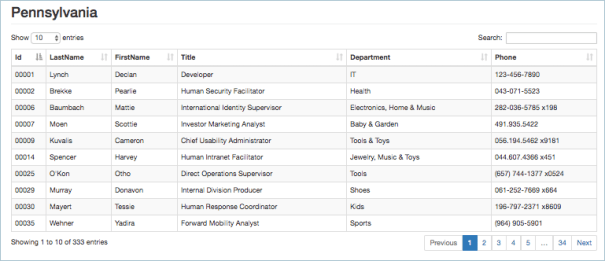
Now that we have our demo data and we have confirmed that it exists when we start the application it is time to add it to the Thymeleaf based UI.
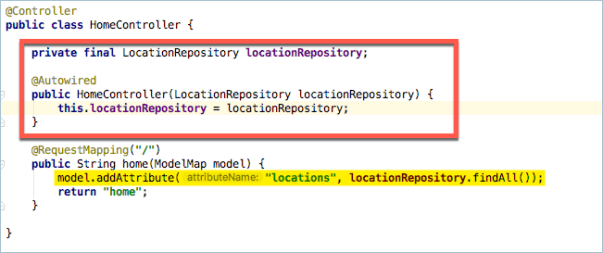
First we need to add it to the data model that is used when the page is rendered. If we return to our HomeController class we need to make a couple of changes. First we need to get access to the LocationRepository bean. We do this by adding an Autowired reference the bean using the same method that we did when building the demo data.
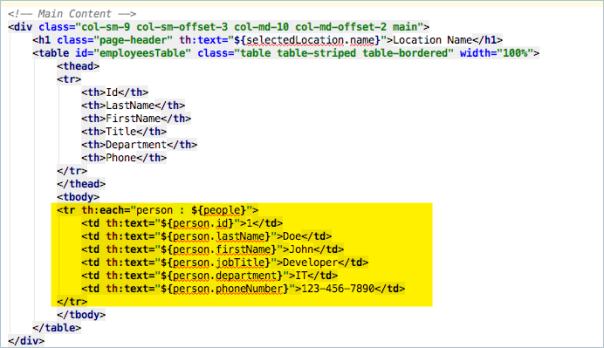
Then we need to add this to the model. The model is pretty much a java map of strings and objects. In the highlighted line below you can see that I’ve used the model.addAttribute method to create an entry called ‘locations’ and the object passed in to that attribute is the findAll() method of the locationRepository.
Now we need to turn our attention to the thymeleaf html page. I’ve added a bunch of other Bootstrap related changes to give the application a basic layout and I’ve decided that the list of locations should appear in the side navigator. I’m building a standard bootstrap styled navigation with some extra Thymeleaf magic.
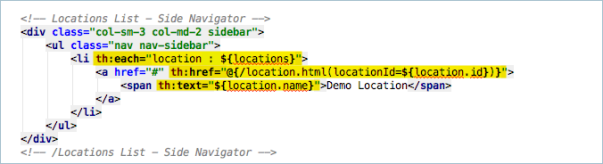
In my LI tag I have a th:each attribute. This is similar to a repeat control in xpages and is written like a loop in java. the ${locations} is the locations attribute from the model and the th:each will loop through them using a variable name of ‘location’ for each iteration.
In the A tag I have a th:href that contains a thymeleaf expression that will be converted to a url. While it may look a little complex its not really that difficult. Firstly the expression is surrounded with @{…} this tells the thymeleaf renderer that the url being generated is absolute to the base of the application. This allows you to move the application on an application server to a different subpath and none of the paths in the application will break. Next is the reference to the html page that is going to be displayed next /location.html. After that is a section in round brackets, anything in here will be converted to parameters on the url and the path surrounded with the ${…} is a reference back to the loops variable and in this case we are pulling the id from the object.
So the th:href will be translated to /location.html?locationId=xx where xx depends on the selected location.
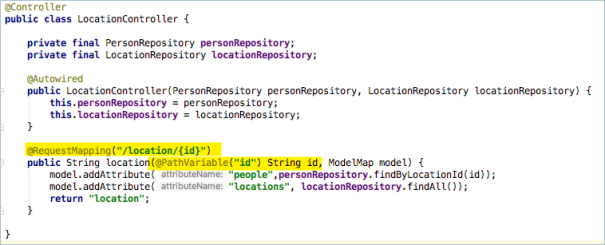
What if you don’t want location.html in the url and want to do something like /location/XX in that case your th:href would look like
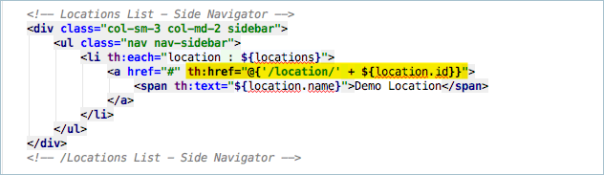
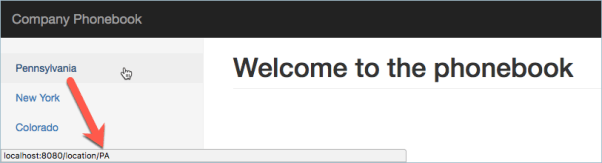
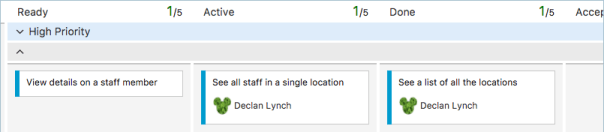
I’m going to leave it like this for my application so that I can show you a great feature in the Spring MVC request mapping controllers next but for now I’v completed my first task of showing a list of the location on the main home page of the application. I can now return to VSTS and drag that card over to the done column and see what is next up to do.
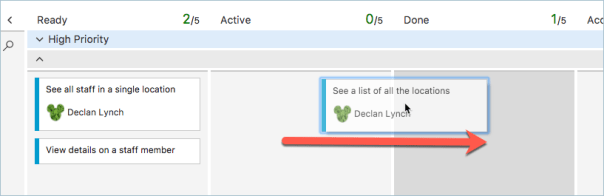
So looks like I’ll be building the location page so that you can see all the staff in a single location. I’ll drag that over to Active and start work on it next.




You must be logged in to post a comment.